

爬取甘肃全省过去三年的天气数据
本文爬取的数据都是学习研究使用,如有侵权,请联系笔者删除:alayama@163.com
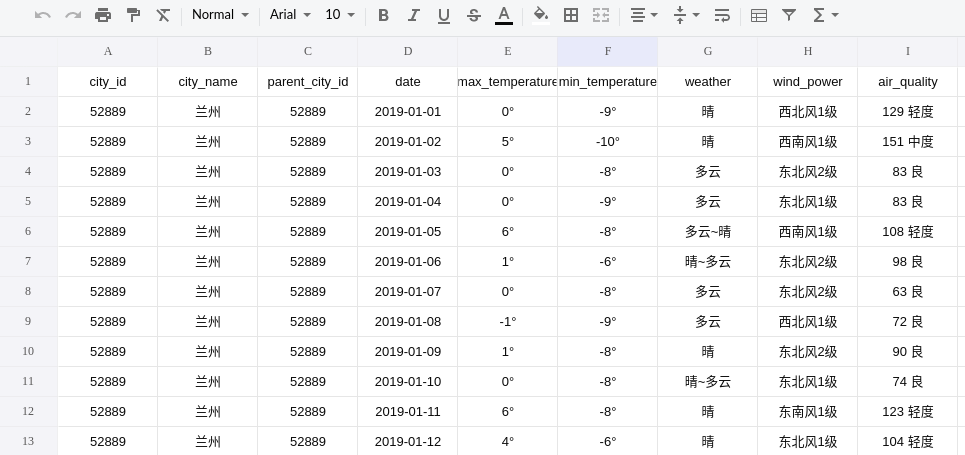
因研究中需要使用到甘肃省全省过去三年(2019年1月1号至2021年4月26号)的天气数据,搜索后发现网上并没有现成的数据集或者接口(阿里云可能有收费接口)。最终决定使用爬虫爬取所需数据。但是笔者之前没有接触过爬虫,于是现学现卖花了两天时间倒腾出来了,最终的数据存为csv文件,如下图:
技术前提:
语言:Python
框架/库:request lxml json pandas
分析准备
爬取的网站为:http://tianqi.2345.com/
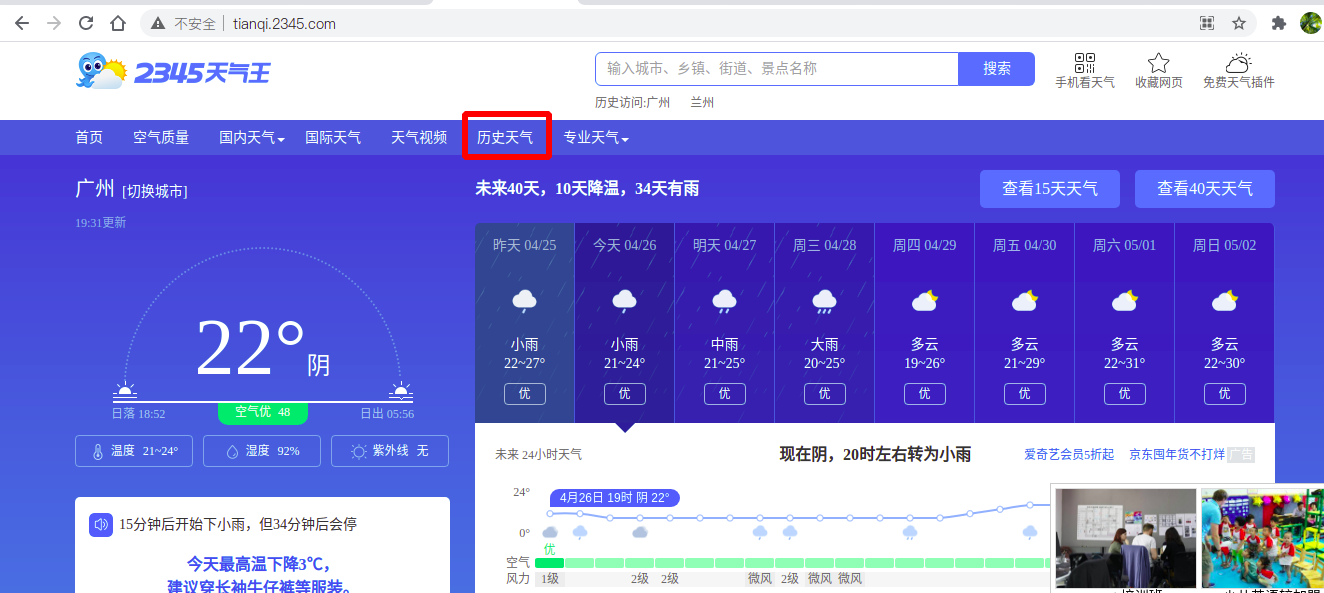
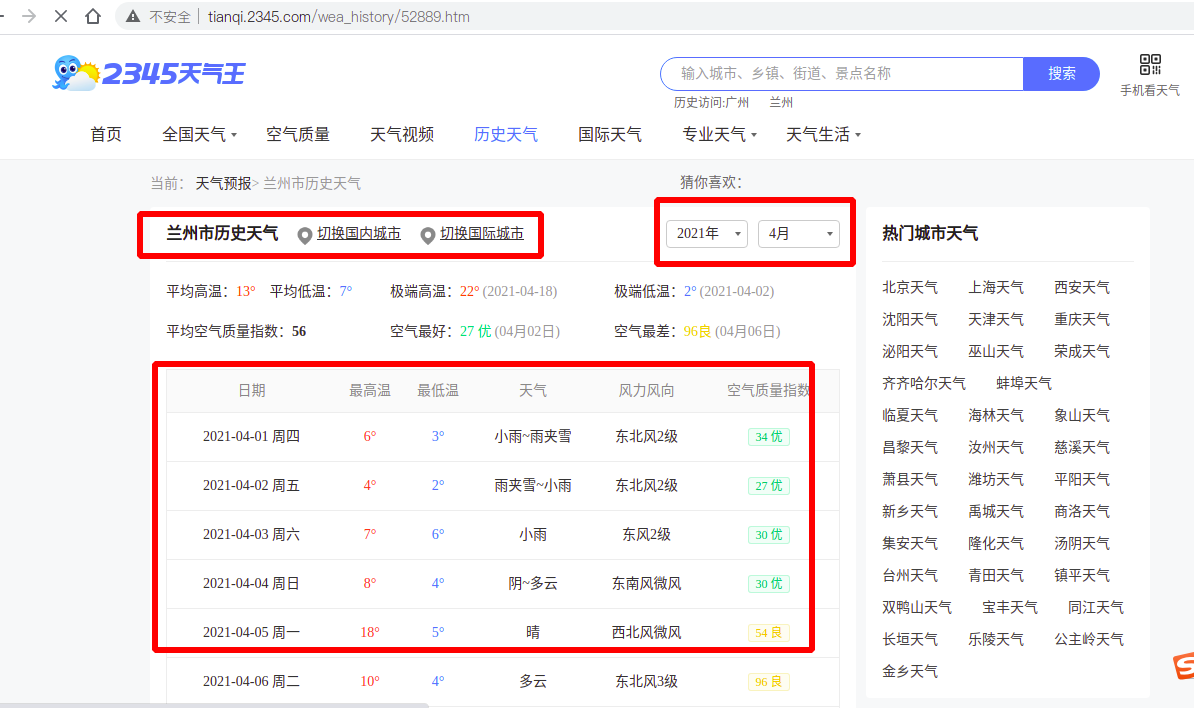
在切换城市时通过开发者工具发现页面会向后台发送请求查询所选择的城市数据
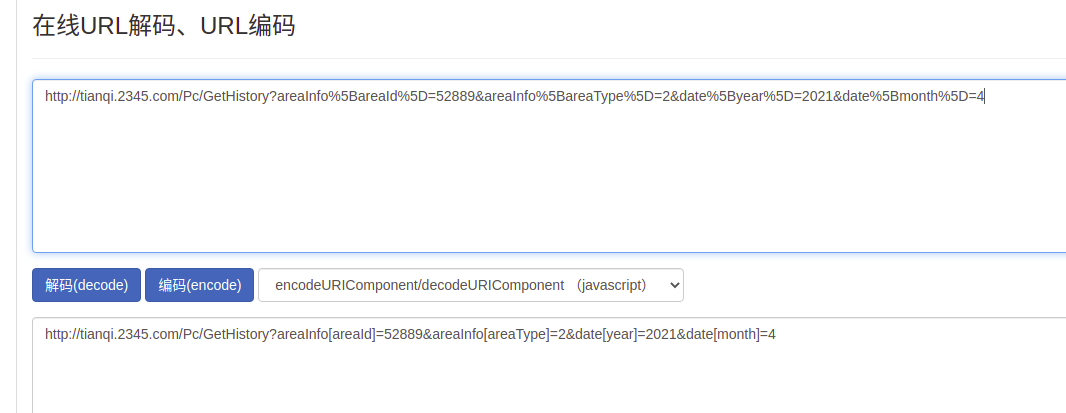
请求url:
http://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=52889&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=4
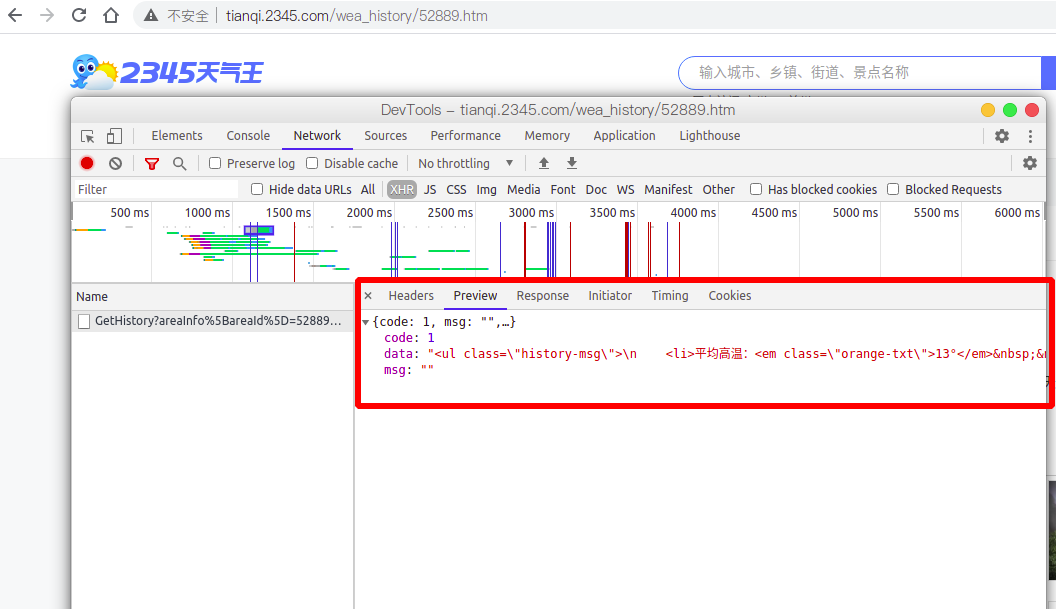
通过url解码后发现这个请求共有4个参数:
areaInfo[areaId]区域id,每个城市的id都不同areaInfo[areaType]区域类型,暂时固定为2date[year]年份date[month]月份
现在分析一下请求的响应结果是什么的样子的。显然,后台返回的是json格式的数据,把刚才的响应结果拷贝到格式化工具中查看:
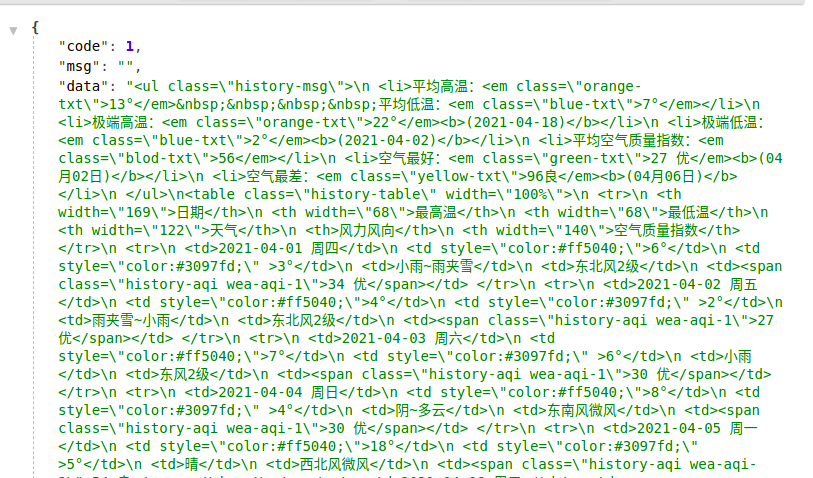
可以看出,后台返回的数据体是html标签数据,所以,后面在处理数据时一定要用到html/xml数据处理框架,这里使用的是lxml
现在,请求url,响应数据结构,请求参数都有了,唯一不清楚的就是城市id,通过开发者工具发现城市选择下拉框中的数据都是通过js生成的,并且在生成的时候没有向后台发请求。
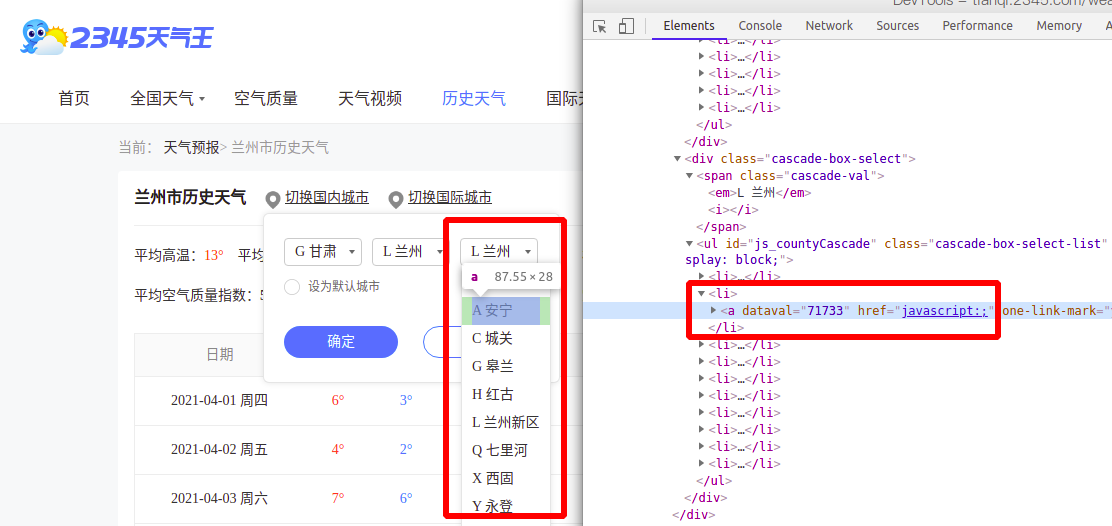
因此可以合理的猜测城市id很可能存在某个js文件中,果不其然,经过检查后发现城市数据存在这个js文件中

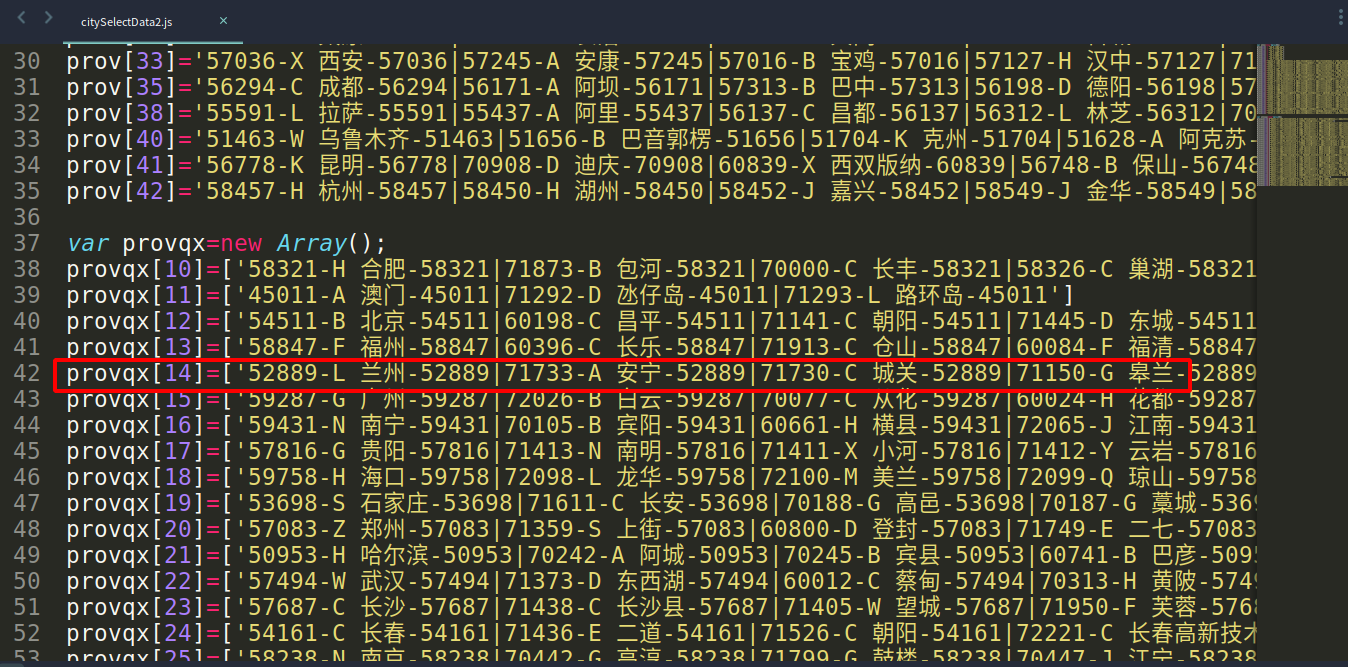
不难看出,甘肃省的数据存在provqx[14]中,它是一个数组,数组中每一项是一个地区市,每一个城市通过符号|分隔,每一个城市的数据又分为三项,通过-分隔,前面的数字是城市id(如:71733),中间是城市名称(如:A-安宁),后面一项是该城市的上级城市(如:52889)。明确了这一点写代码就非常容易了。
OK,分析工作已经完成了,接下来就是代码时间。
代码实现
整个代码流程如下:
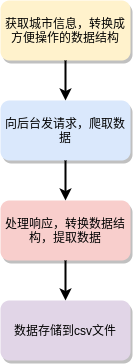
- 导入依赖
import requests
import json
from lxml import etree
import pandas as pd
- 获取所有城市信息
数据结构如下:
[
{
"city_name": "兰州",
"city_id": 52889,
"city_parent": 52889
}
]
定义方法,提取所有的城市信息,返回一个列表/数组
def get_city_id_list():
"""
获取所有城市名称,id,上级城市列表
:return:
"""
# 从之前的js文件中复制
provqx = [
'52889-L 兰州-52889|71733-A 安宁-52889|71730-C 城关-52889|71150-G 皋兰-52889|71734-H 红古-52889|72124-L 兰州新区-52889|71731-Q 七里河-52889|71732-X 西固-52889|60473-Y 永登-52889|60468-Y 榆中-52889',
'56080-G 甘南-56080|70039-D 迭部-56080|71430-H 合作-56080|70058-L 临潭-56080|70060-L 碌曲-56080|70061-M 玛曲-56080|70072-X 夏河-56080|70076-Z 卓尼-56080|60487-Z 舟曲-56080',
'60472-L 陇南-60472|60481-C 成县-60472|60482-H 徽县-60472|60483-K 康县-60472|60167-L 礼县-60472|70056-L 两当-60472|70038-T 宕昌-60472|70069-W 文县-60472|71420-W 武都-60472|70073-X 西和-60472',
'52896-B 白银-52896|71358-P 平川-52896|72123-B 白银区-52896|70051-H 会宁-52896|60334-J 靖远-52896|60475-J 景泰-52896',
'52995-D 定西-52995|71155-A 安定-52995|60477-L 陇西-52995|60166-L 临洮-52995|60479-M 岷县-52995|60478-T 通渭-52995|60469-W 渭源-52995|70075-Z 漳县-52995',
'52675-J 金昌-52675|71736-J 金川-52675|60471-Y 永昌-52675',
'52533-J 酒泉-52533|71355-A 阿克塞-52533|71356-Y 玉门-52533|60163-D 敦煌-52533|71092-G 瓜州-52533|70054-J 金塔-52533|60164-S 肃北-52533|71738-S 肃州-52533|70074-Y 玉门镇-52533',
'71129-J 嘉峪关-71129',
'52984-L 临夏-52984|71357-J 积石山-52984|70041-D 东乡-52984|60485-G 广河-52984|70046-H 和政-52984|70055-K 康乐-52984|72125-L 临夏市-52984|72126-L 临夏县-52984|60484-Y 永靖-52984',
'53915-P 平凉-53915|70037-C 崇信-53915|70050-H 华亭-53915|70052-J 泾川-53915|70053-J 静宁-53915|71153-K 崆峒-53915|70057-L 灵台-53915|60165-Z 庄浪-53915',
'53923-Q 庆阳-53923|70049-H 环县-53923|70047-H 华池-53923|60333-H 合水-53923|60476-N 宁县-53923|71154-Q 庆城-53923|60161-X 西峰-53923|60470-Z 正宁-53923|60480-Z 镇原-53923',
'57006-T 天水-57006|70042-G 甘谷-57006|71151-M 麦积-57006|70066-Q 清水-57006|70065-Q 秦安-57006|71739-Q 秦州-57006|70070-W 武山-57006|60474-Z 张家川-57006',
'52679-W 武威-52679|70045-G 古浪-52679|71735-L 凉州-52679|70064-M 民勤-52679|71152-T 天祝-52679',
'52652-Z 张掖-52652|70044-G 高台-52652|71737-G 甘州-52652|70059-L 临泽-52652|70063-M 民乐-52652|70068-S 肃南-52652|70067-S 山丹-52652']
city_list = []
for i in provqx:
city_info_list = i.split('|')
for city_info in city_info_list:
item = {}
city_name = city_info.split(' ')[1].split('-')[0]
city_id = city_info.split(' ')[0].split('-')[0]
city_parent = city_info.split('-')[2]
item['city_name'] = city_name
item['city_id'] = city_id
item['city_parent'] = city_parent
city_list.append(item)
return city_list
- 向后台发请求,爬取数据
根据之前的分析,现在四个参数都已经知道了,直接使用request库向后台发请求,request库使用方法也比较简单,没有了解的读者可以简单了解一下即可。
def request_weather_info(city_info: {}):
"""
获取天气信息
:param city_info: 城市信息
:return:
"""
# 请求url
url = 'http://tianqi.2345.com/Pc/GetHistory'
# 设置请求头,可选
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
}
city_name = city_info['city_name']
city_id = city_info['city_id']
city_parent = city_info['city_parent']
# 结果集,封装当前城市近三年的所有数据
result = []
# 循环请求数据
for year in [2019, 2020, 2021]:
for month in range(1, 13):
# 设置请求参数
params = {'areaInfo[areaId]': city_id, 'areaInfo[areaType]': 2, 'date[year]': year, 'date[month]': month}
# 发送get请求
response = requests.get(url, params=params, headers=headers)
# 获取请求数据,因为响应结果是json字符串,需要先转换为字典数据结构
response_data = json.loads(response.content.decode())
# 获取天气数据体,之前有分析过
data = response_data.get('data')
# 使用lxml中的etree模块将天气数据转换成html树
html = etree.HTML(data)
# 使用xpath语法解析数据
weather_info = html.xpath('//table/tr[position()>1]')
for item in weather_info:
single_day_weather = []
# 日期
date = item.xpath('./td[1]/text()')[0].split(' ')[0]
# 最高温度
max_temperature = item.xpath('./td[2]/text()')[0]
# 最低温度
min_temperature = item.xpath('./td[3]/text()')[0]
# 天气
weather = item.xpath('./td[4]/text()')[0]
# 风力
wind_power = item.xpath('./td[5]/text()')[0]
# 空气质量,测试中发现,有些地方某月份的空气质量数据不存在,会抛出异常,这里捕捉一下,如果不存在就置为空
air_quality = ''
try:
air_quality = item.xpath('./td[6]/span[1]/text()')[0]
except:
air_quality = ''
print(date)
print(year, month, city_info)
print(air_quality)
print(type(air_quality))
single_day_weather.append(city_id)
single_day_weather.append(city_name)
single_day_weather.append(city_parent)
single_day_weather.append(date)
single_day_weather.append(max_temperature)
single_day_weather.append(min_temperature)
single_day_weather.append(weather)
single_day_weather.append(wind_power)
single_day_weather.append(air_quality)
result.append(single_day_weather)
# pd.DataFrame(result).to_csv('./weather.csv', mode='a', index=None)
# result = []
return result
- 最后执行相关方法,保存数据
if __name__ == '__main__':
for i in get_city_id_list():
pd.DataFrame(request_weather_info(i)).to_csv('./weather.csv', mode='a', index=None)
print('结束...')
数据修整
因为是多次追加保存,所以csv文件中有很多相同的column行,这里使用pandas删除一下就好了
import pandas as pd
import numpy as np
import dask.dataframe as dd
if __name__ == '__main__':
# weather_csv = pd.read_csv('./weather.csv')
weather_csv = dd.read_csv('./weather.csv', dtype={'a': str, 'c': str})
weather_csv = weather_csv.drop(labels='j', axis=1)
weather_csv = weather_csv.drop_duplicates()
weather_csv.to_csv('./weather_new_3.csv', mode='w', index=None)
print('结束....')
最终的数据长这样(表头经过手工修改,默认是0, 1, 2。。。无伤大雅):
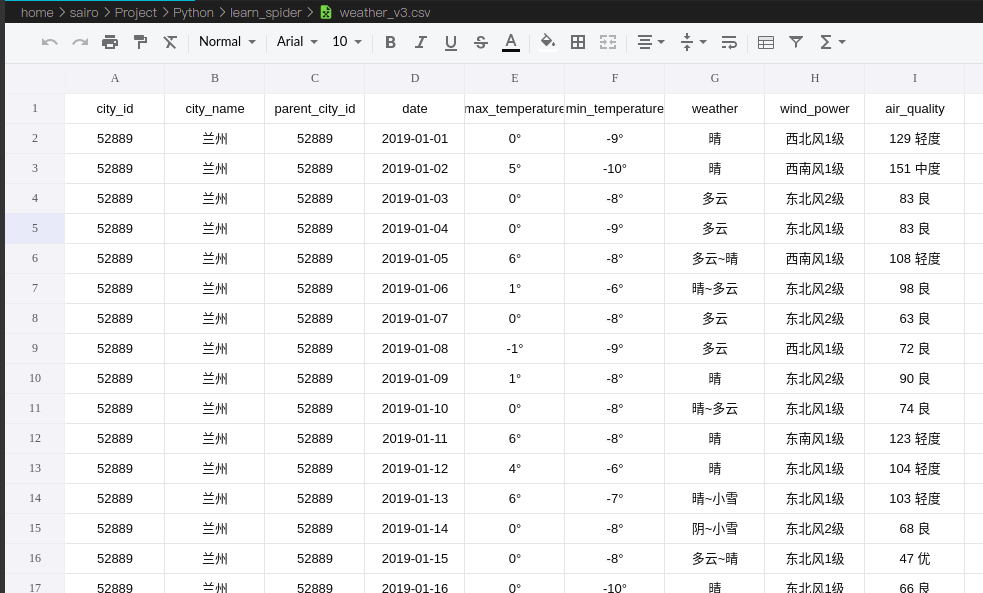

因为有的地方有些月份空气质量值缺失,如果要使用的话可能需要做一些处理