


问题描述
因研究需要,今天在了解seaborn 这个可视化框架,但是在第一行代码就报错了。。好嘛,看看啥错:
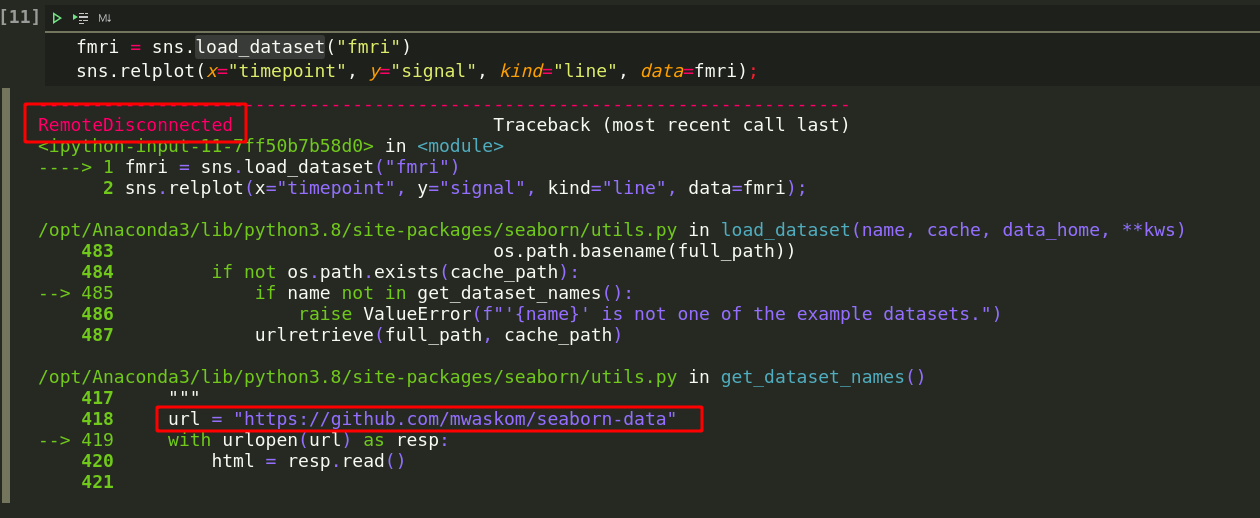
看到这我就知道大概啥问题了,国内网络对国外的网站很不友好。。

解决方案
解决方法也很简单,主要有以下三种:
- ke | xue | shang | wang 工具
- 配置代理
- 单独把数据集下载下来,拷贝到本地
方法一
ke | xue | shang | wang 懂的都懂,略。
方法二
配置代理其实跟方法一原理相同。seaborn在调用load_dataset方法时会先检查本地是否已经下载过数据,如果本地没有数据就会向远程仓库(https://github.com/mwaskom/seaborn-data)发请求,下载指定的数据集。Python中一般有urllib.request和requests两个http请求工具,后者是前者进一步的封装。检查发现,seaborn使用的是urllib.request
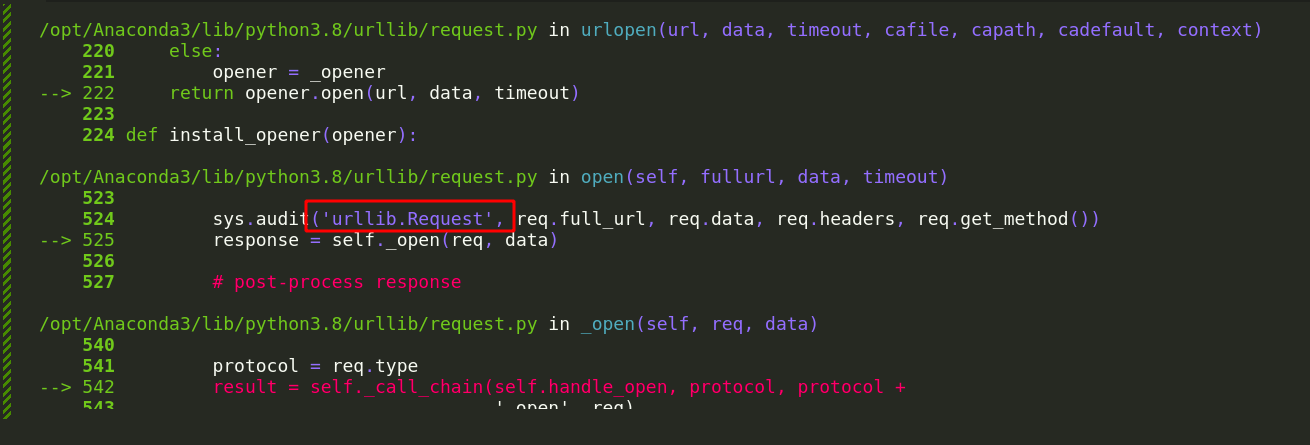
配置代理就是将请求转发给指定的代理服务器,代理服务器再将请求转发给目的服务器,最后代理服务器将响应数据返回给客户端。

import urllib.request
proxy = urllib.request.ProxyHandler({'http': "http://localhost:2340",'https': "http://localhost:2340"})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
方法三
前面说过,seaborn会先检查本地是否有数据,有的话就直接加载(调用pandas.read_csv),默认情况下seaborn会检查当前用户主目录下的seaborn-data文件夹内是否已存在数据集,有的话直接加载。只需要到远程仓库(https://github.com/mwaskom/seaborn-data)把对应的数据集下载并拷贝到用户目录下的seaborn-data目录就OK。
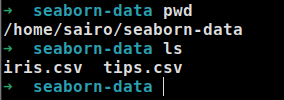
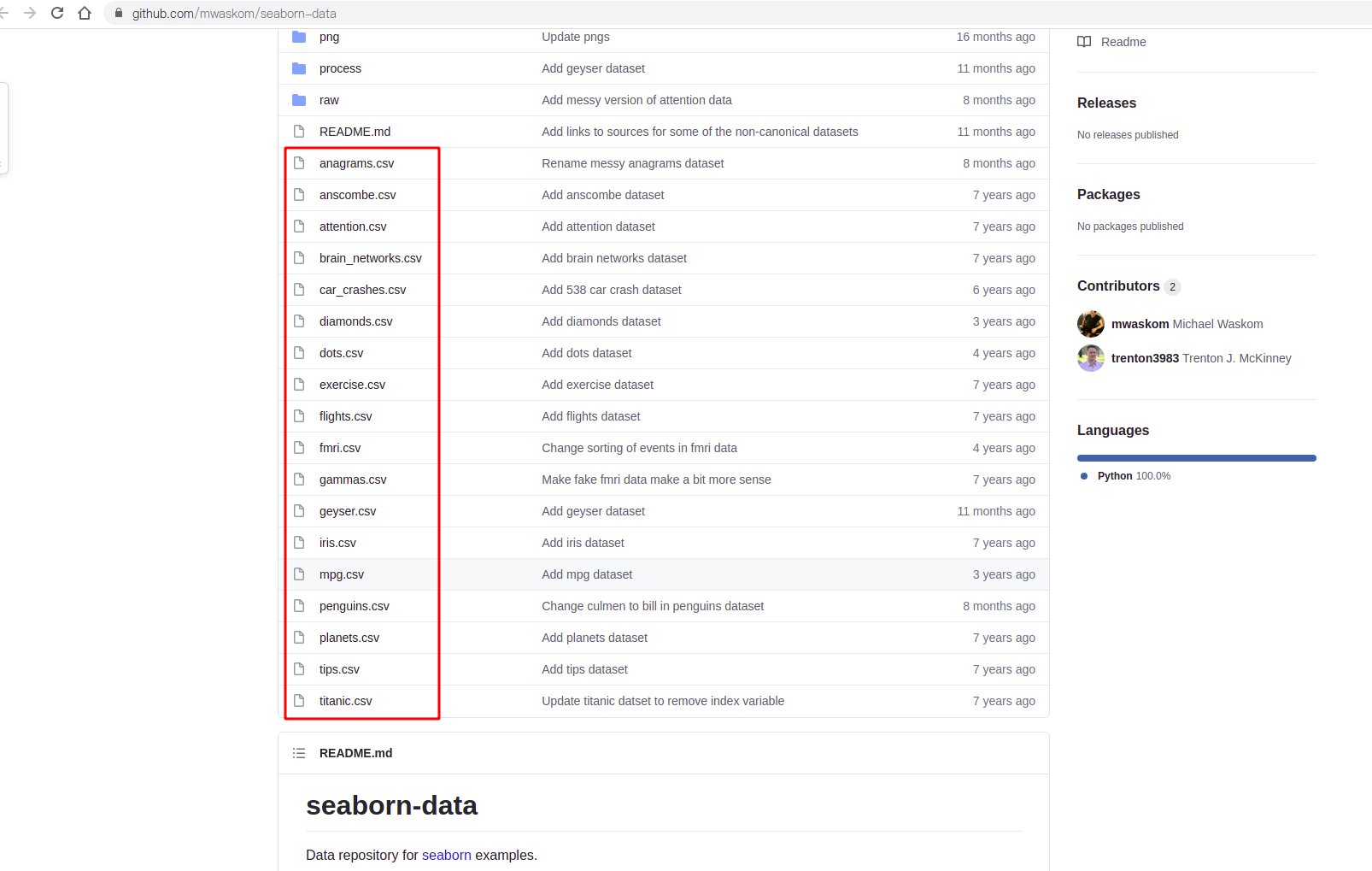
完整示例
# 绘图
import seaborn as sns
# 数值计算
import numpy as np
# sklearn中的相关工具
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
# 逻辑回归
from sklearn.linear_model import LogisticRegressionCV
# tf.keras中使用的相关工具
# 用于模型搭建
from tensorflow.keras.models import Sequential
# 构建模型的层和激活方法
from tensorflow.keras.layers import Dense, Activation
# 数据处理的辅助工具
from tensorflow.keras import utils
import urllib.request
"""
# 配置代理
proxy = urllib.request.ProxyHandler({'http': "http://localhost:2340",'https': "http://localhost:2340"})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
"""
# 读取数据
iris = sns.load_dataset("iris")
# 展示数据的前五行
iris.head()
# 将数据之间的关系进行可视化
sns.pairplot(iris, hue='species')
参考资料
https://seaborn.pydata.org/tutorial/relational.htmlhttps://zhuanlan.zhihu.com/p/49035741https://blog.csdn.net/lw_power/article/details/77946852
